
IT and security leaders have difficult roles: They must support business initiatives, manage large numbers of vendors, maintain hybrid IT infrastructure, and defend against cyber-attack. Now, with new data protection and privacy laws, security and privacy practices are converging, and IT and security need to work with stakeholders in privacy, compliance, risk, and legal.
And as if that wasn't enough, there is another challenge: prioritizing and balancing the protection and usability of confidential data to drive value for the business.
New laws to protect the personal data of consumers, including the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA), have created some anxiety among organizations that use big data analytics. They're worried they won't be able to perform analytics on their consumer data without violating the privacy protections in the new laws.
The CCPA, for example, states that organizations have a "duty to implement and maintain reasonable security procedures and practices" to protect consumer data. What's reasonable hasn't been determined yet, but if an organization wants to play it safe when it comes to compliance with the law, it will consider adopting a data-centric approach to security and protect its data at the field level and not rely on infrastructure encryption—encrypting storage, file systems, and database containers—which has proved to be vulnerable to attackers.
"Field level" is a reference to the fields in a database where data is stored. For example, the "Last Name" field would contain the last name of a consumer. One of the biggest objections I hear from customers is that protecting data at the field level is going to drastically reduce their ability to perform data analytics when the dataset includes personally identifying information (PII) protected by law.
While business users must adapt to the privacy priorities established by new laws, all is not lost. Here's why you need to build security and privacy into your big data analytics for the long haul.
Format-preserving encryption is key
Organizations run into trouble when trying to protect data to comply with the requirements of laws such as the CCPA when they use limited or out-of-date methods to do it.
For instance, consider the practice of masking, a way to hide some or all sensitive data in a field. Redactions in documents released by the government are a form of masking. But when you use masking on database data, it can destroy valuable relationships within that data.
Say you have a database of insurance data. In the figure below, each person is issued a unique national ID (the "Nat. ID" column).
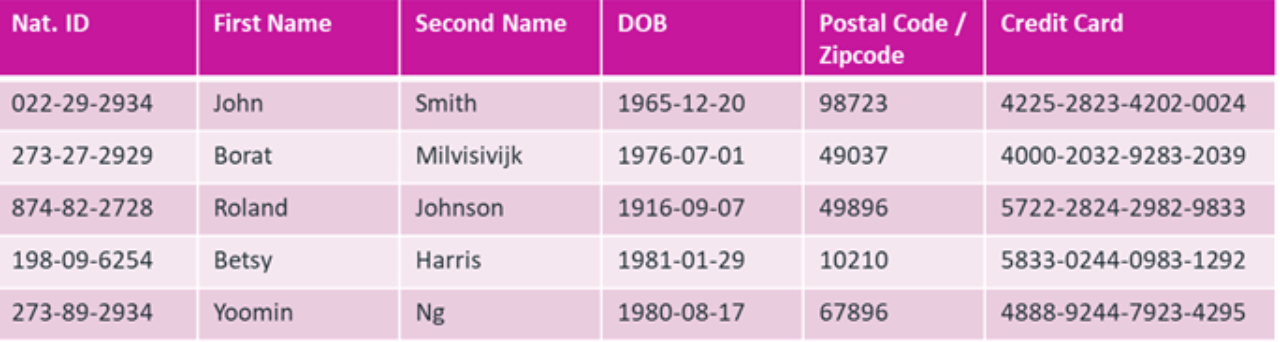
The relational database management system (RDBMS) uses this to identify account holders. In RDBMS terminology, the "Nat. ID" column is the primary key field.
When the column appears in other database tables in the system, it's referred to as a "foreign key." The relationship between foreign keys and primary keys is called "referential integrity," and combining data across two tables is called a "join." Referential integrity is what provides accurate and complete information.
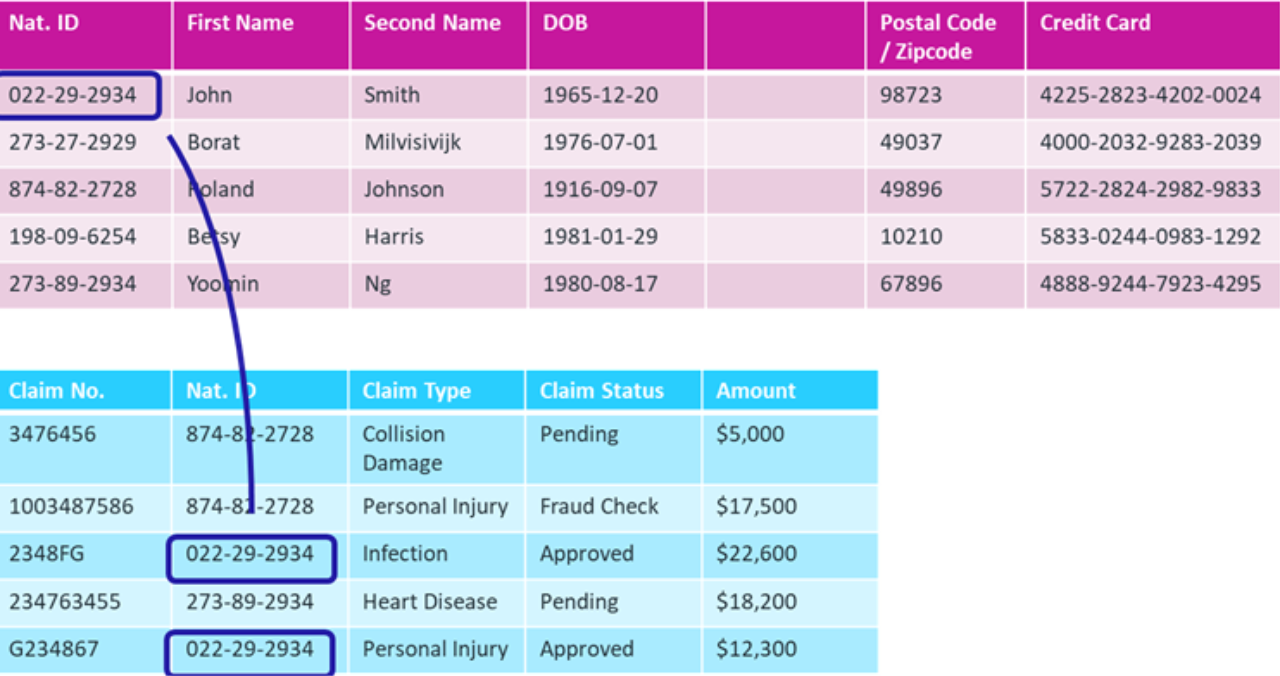
Now let's see what happens when the primary key is masked.
When you partially mask the national ID, some value is retained in the protected dataset, but referential integrity is broken. Anyone who wants to analyze this dataset won't know whether a given person had one, two, or three claims. Although the name of the person is not important, the number of claims by a single person may be valuable business information.
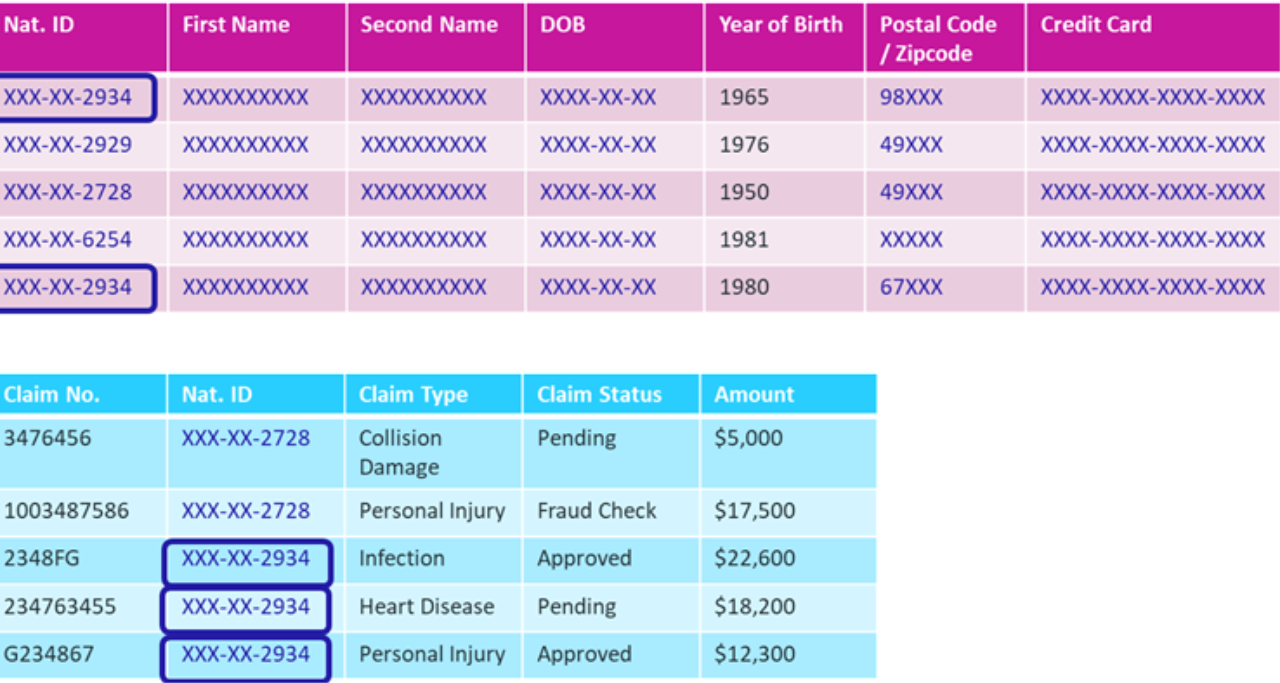
By using more modern methods, however, you can use encryption to mask data without gutting its value. You do that with format-preserving encryption (FPE). With FPE, the ID in our example is turned into an encrypted version of itself that looks like a genuine ID.
This technology brings several benefits. You preserve the relationships in the database connected to the information in the data fields. In the example, you can find all the claims connected to an ID because that ID's encrypted value is just substituted for the original ID.
If the encrypted data is stolen, it's worthless to the thief because it's not real information—not a real ID, birth date, last name, or anything else.
Because the formatting is preserved by the encryption, the data is easier for legacy systems to digest, as they're programmed to work in those formats.
Size of datasets won't balloon. Encryption can expand the size of data stores, but since FPE produces data that reflects the original, the size of encrypted data will remain the same.
One problem with masking is that once you've masked something it's hard to access the original. You can erase a redaction, but it's unlikely you'll see what's under it. Since FPE data is encrypted, its original value can be recovered through decryption.
Quasi-identify the data attributes
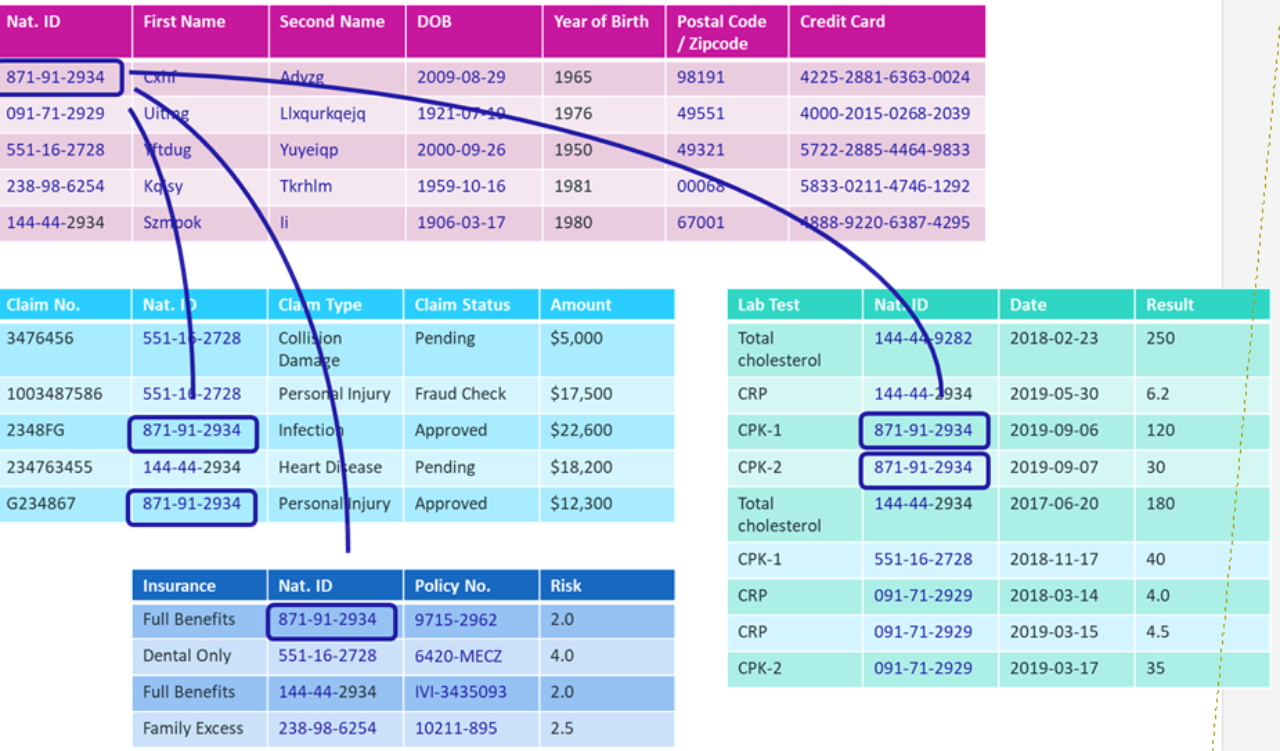
When determining what fields in a dataset need to be encrypted, pay close attention to quasi-identifying data attributes such as dates of birth and fine-grained geolocation coordinates or physical addresses, such as postal codes and ZIP codes.
In isolation, or in source transactional application databases, such identifying data can be reasonably innocuous. But when combined into a single database, such as a big data lake or a data warehouse that has a much larger user community, the risk to privacy is greatly increases.
For example, when looking closely at a large dataset of PII, you could make certain inferences that enable you to re-identify a person without needing to know the values in the original data. For instance, how many people are over the age of 95, live within a small US ZIP code, and have a specific set of health conditions?
For the data analytics practitioner, this means these quasi-identifying attributes may need to be encrypted and then decrypted on a more regular basis than other direct identifying attributes.
In addition, it may be valuable to store parts of these quasi-identifying attributes, such as the year of birth, to enable further age-based analytics without needing to decrypt the original full date of birth.
The need to encrypt and decrypt quasi-identifying data, however, can be reduced by restricting access to it. All data analysts need not have access to that level of PII. Usually it can be restricted to smaller groups that have higher privileges. That's why cryptographic performance remains vital to proper adoption of privacy measures, while limiting disruption to the business.
There are also ways to make more thorough data analytics possible with reduced decryption. For example, it might be valuable to preserve the descriptive statistics of a dataset—mean, variance, and so forth—after the data comprising it has been encrypted or hashed. By combining the properties of encryption with well-known statistical functions, it's possible to preserve a particular distribution.
Encryption lets you move forward
The GDPR and CCPA will challenge organizations that want to perform big data analytics on datasets with PII, but by using encryption you can still produce meaningful analytics from that data.
Keep learning
Get up to speed on unstructured data security with TechBeacon's Guide. Plus: Get the Forrester Wave for Unstructured Data Security Flatforms, Q2 2021.
Join this discussion about how to break the Ground Hog Day repetition with better data management capabilities.
Learn how to accelerate your analytics securely into the cloud in this Webinar.
Find out more about cloud security and privacy, and selecting the right encryption and key management in TechBeacon's Guide.
Learn to appreciate the art of data protection and go behind the privacy shield in this Webinar.
Dive into the new laws with TechBeacon's guide to GDPR and CCPA.
