
In my first article in this two-part series, Serverless computing: 5 things to know about the post-container world, I hopefully whetted your interest in serverless apps, because this second installment offers a technical discussion about this new way to build and run applications. To put it another way, my first answered the question “Why serverless?” Now I am answering, “What are serverless apps and how do they work?”
Serverless: The New 'aaS'
Perhaps the most natural shorthand for serverless apps is to continue the “aaS” formulation, in which serverless is FaaS: functions as a service. Essentially, a serverless app is one in which you upload a function—i.e., a function-bounded code segment—to the FaaS offering, and it takes responsibility for running it when it is called.
So unlike IaaS or CaaS (containers as a service), where the user takes responsibility for both inserting the code and running the execution environment, in FaaS the user takes responsibility for inserting (uploading) the code and defining how the provider should run it.
This typically takes the form of naming the function, defining the conditions under which it should be run, and providing any configuration required to allow the code to speak to resources outside the execution boundary (e.g., defining an AWS Simple Notification Service that the code will use to send a message to the user that some work has been executed; in addition to defining the SNS, it is necessary to configure it so that the Lambda function can talk to it).
I used the example of Lambda deliberately. It is the only cloud-based FaaS offering available on a production basis. Both Google and Microsoft have FaaS offerings, but at this point they are in a pre-production release state. IBM offers OpenWhisk as a BlueMix service, but again on an experimental basis; IBM also distributes OpenWhisk as an open-source project, but I doubt anyone using it on-premises has moved beyond an exploratory stage.
The rest of this discussion uses Lambda as an example, but each FaaS implementation is similar. A user-defined function is uploaded to the FaaS environment, which takes responsibility for loading and executing the function as required.
Of course, the magic is in how that loading and executing occurs!
Preparing the FaaS function with the Lambda wizard
Getting a function ready to execute is pretty straightforward. Using Lambda and the node language as an example, you run the Lambda wizard to upload the node function, or if the function is quite simple, use the code editor right inside the wizard to write—or more likely paste—the code into Lambda.
The Lambda environment offers only a couple of standard libraries devoted to accepting URLs and interacting with AWS itself; any other library modules that are needed by the function must be uploaded along with the function’s code in a zip file.
The remainder of the wizard is devoted to defining how the function is called (addressed in the next section), uploading the code, setting the configurations that will govern the conditions under which the function will execute (e.g., how much memory the function will have), giving the function a name by which it will be called, and defining what kind of role it will have (e.g., is it an S3 execution role, by which it means, does it execute as a result of an S3 event?).
That’s it. Once the code is in place, with its configuration defined and the way it will be called identified, it’s ready to go.
Events trigger serverless functions
So how does a FaaS function get executed? In a word, events. When the FaaS service receives an event directed toward a particular function, it quickly loads the function’s code and delivers the event’s payload to it.
The payload is quite restricted in terms of how much data it can carry. For Lambda, the payload data limit is 128 KB. For functions that are designed to operate on larger data objects, the typical practice is to pass in some metadata (e.g., an object bucket identifier in which the larger data object has been placed). The function then uses the metadata to retrieve the object from the bucket and operate on it.
When an event is delivered to the function—remember, the mechanism that triggers the event must know its name, which is defined during the Lambda creation phase—the code executes, making use of what is delivered in the event payload to inform it of some resource to operate on.
What kind of events can trigger a FaaS function? As the figure below illustrates, the events can arrive from outside the FaaS environment or they can occur as a result of some state change within the FaaS environment.
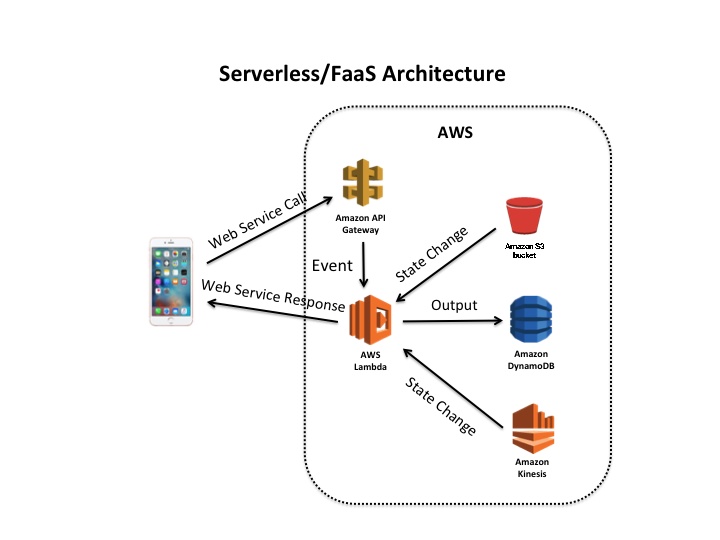
So, an event might enter the FaaS environment from an external device, such as a mobile app or IoT device. Likewise, a browser-based application might forward a call to the FaaS environment, which would forward it to the FaaS function. For these kinds of external events, something must accept the communication and translate the communication format into a FaaS function call. Within AWS, that translation occurs via the API gateway. It knows how to receive a web service call and convert it into a Lambda function call.
Inside AWS, the Lambda function can be triggered by a state change in some AWS resource, which can be an S3 bucket, a DynamoDB table, a delivered Kinesis event, or a number of other resources. When the state change occurs, AWS calls the Lambda function and delivers the payload, which might be the entire Kinesis event or the S3 object metadata (i.e., the object’s URI).
The Lambda function takes the payload input, operates on it, and most likely does something. The “hello world” serverless canonical example is a FaaS function that is called when an image is placed into object storage and transforms the image by changing its size or perhaps creating a thumbnail.
In this kind of example, the FaaS function might import the image from one bucket, transform it into the desired format(s), and then place the new image(s) into another bucket. It could then send a message to the function caller via a web service, alerting it to the existence of the new image(s), or, indeed, another Lambda function could be called, triggered by the state change of the output bucket.
FaaS function execution
The critical difference between FaaS functions and the “legacy” approach in which code is installed into a long-running execution environment (a virtual machine instance or a container) is that the FaaS function execution environment is transient. The function is loaded, run, and then terminated, i.e., torn down. So there’s only a single run-through of the code, although the code can, of course, have internal loops to execute a set of code multiple times.
In other words, FaaS functions have a limited lifetime and need to execute and complete their work during that lifetime. And there is no persistence-of-execution-environment state across function instantiations. If, as in the just-cited example, the image transformation function is called a number of times, and a running tab of how many images have been transformed is needed, that tracking needs to occur outside the function’s own context, perhaps in an external database. Any internal context is lost forever when the function terminates upon completion.
The flip side of this approach is that, while a given function may only live for a limited timeframe, a heavy workload will be spread across what can be an arbitrarily large number of executing functions. If one FaaS function is running and another event arrives or state change occurs, Lambda will fire off another function. This can scale to hundreds or even thousands of simultaneously running functions. This is quite unlike the “legacy approach,” in which a heavy load must be met by the user launching more execution environments to manage the load, or by using asynchronous traffic management mechanisms (e.g., a message queue), which imposes high execution latency.
FaaS limitations
FaaS functions operate under a set of constraints. This is because the very nature of FaaS is that the provider seeks to juggle a constant call-and-terminate flow to facilitate high resource utilization. Naturally, the provider hopes this flow will be heavy, because that is how the provider makes money from FaaS. Tim Wagner, general manager of Lambda, uses the term “bin packing” to described how AWS attempts to obtain efficiency in Lambda execution, all in the service of high utilization.
Consequently, there are a number of limitations for Lambda functions. Two have been mentioned, payload size and execution time. As regards the latter, Lambda limits functions to five minutes of execution time; whether the function is complete or not, it’s done.
Other limitations are:
Ephemeral disk size: 512 MB
Number of file descriptors and execution threads: 1,024
Event payload size: 128 KB
State change payload size input and output: 6 MB
Look for the appropriate workloads
I hope this piece has given you a sense of the power of serverless/FaaS functions. They’re not right for every application or every workload, but for appropriate workloads, they are a fantastic solution. Freeing oneself from responsibility for managing long-running execution environments while being able to quickly respond to erratic workloads is a fantastic benefit.
And serverless/FaaS functions are a great match for IoT devices that emit events (typically with small payloads). As the IoT world gears up, many back ends will need to be able to handle millions or billions of events. Trying to manage a fleet of virtual machines or containers to handle that load, particularly if erratic, would be a nightmare. Using serverless/FaaS functions makes that task tractable.
Of course, there are challenges associated with serverless/FaaS. It’s a new application design paradigm, and the field is so new that there are few established best practices or complementary tooling. However, serverless/FaaS is so promising that one should not hesitate to move forward with exploration and experimentation. I expect this will mature quickly and become a significant part of every company’s application portfolio.
Keep learning
Choose the right ESM tool for your needs. Get up to speed with the our Buyer's Guide to Enterprise Service Management Tools
What will the next generation of enterprise service management tools look like? TechBeacon's Guide to Optimizing Enterprise Service Management offers the insights.
Discover more about IT Operations Monitoring with TechBeacon's Guide.
What's the best way to get your robotic process automation project off the ground? Find out how to choose the right tools—and the right project.
Ready to advance up the IT career ladder? TechBeacon's Careers Topic Center provides expert advice you need to prepare for your next move.
