
Continuous delivery (CD) is a specific set of practices for reliable software delivery that's achieved by automating build and deployment and testing software changes. However, many organizations screw up their approaches to CD by not adopting some key practices.
Over the past seven years, I have helped over 30 establishments in various parts of the world adopt CD, and I have seen several repeated mistakes. Here are nine you should avoid.
1. Not reading 'Continuous Delivery'
Amazingly, some people claim to be doing CD, and yet they have not read the book Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation, by Jez Humble and Dave Farley. This is where the term continuous delivery was defined. Yes, technically the phrase is also in the Agile Manifesto, but the notion of rapid, regular, reliable releases that most people think of with the phrase was codified in this 2010 book. Most importantly, CD does not require that code changes be pushed to production on every change; that’s continuous deployment. That might be useful in your context, but you'll get massive benefits from following the CD practices even with more selective releases.
The way in which the chapter subheadings are written in the book means that you can use them as a kind of checklist or progress indicator for your organization. The contents pages from the book can be printed out and stuck on a wall to act as a progress chart. I have recently collated the recommendations from the book in a useful, free online tool at cdchecklist.info, where you can see the checklists in action.
The online continuous delivery checklist tool at cdchecklist.info.
2. Using long, slow deployment pipelines
Another common screw-up I see is that organizations create deployment pipelines that have many steps in sequence, leading to a long wait between committing code to version control and seeing the changes in production (live). These long, slow deployment pipelines kill the rapid feedback essential for teams to be able to act effectively on failures and learn from monitoring.
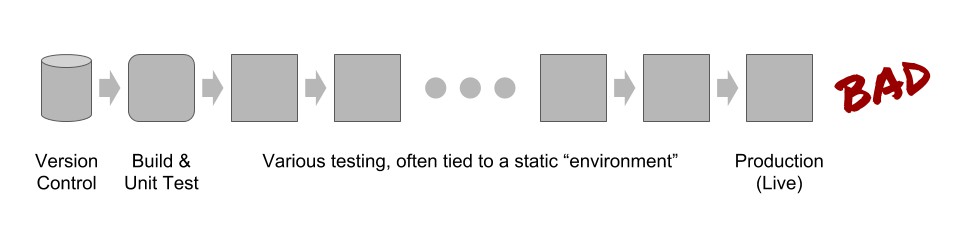
Long, slow deployment pipelines break rapid feedback from the deployment process.
Instead, use short, wide deployment pipelines that give teams and product managers enough flexibility to decide which tests to run based on the nature of each specific change. After committing code to version control, build the binaries and run unit tests (and perhaps code metrics checks). Then run a set of automated acceptance tests based on application features (which include both user-facing and operational features).
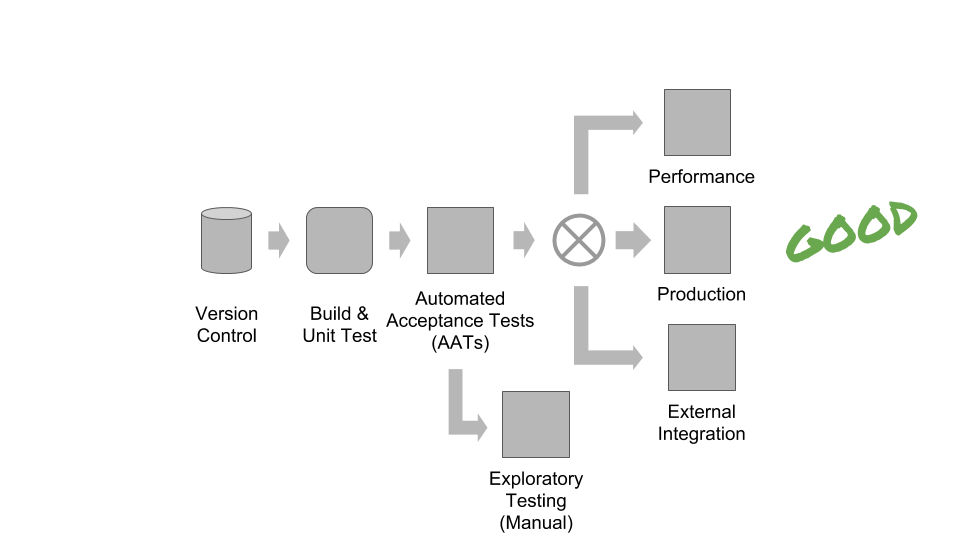
Short, wide deployment pipelines optimize for rapid feedback and rapid deployment decisions.
If these checks pass, then by definition the team or product manager may have the confidence to deploy to production. They also have the option to run additional checks if they wish, but the additional checks are not mandatory and depend on the context of the exact change made.
3. Thinking 'CD is not for us'
Together with a great team, I have run the Pipeline Conference in London since 2014. Pipeline was the first conference in Europe dedicated to CD. At both Pipeline and its sibling meetup group, LondonCD, we have had over 130 speakers from around the world and many different organizations talking about how they have used CD principles to make software delivery reliable and rapid. The variety of situations in which CD works is what makes it such a valuable approach.
The wide applicability of CD principles is borne out by my consulting experience. In fact, every software delivery situation I have encountered in the last seven years has (or could have) benefited from following almost every CD principle and practice—without exception. Yes, continuous delivery is for you!
4. Having no effective logging or metrics
Many organizations try to adopt the more rapid pace of change enabled by CD practices without a solid foundation of operational telemetry. This lack of metrics and logging begins to hurt as deployments become more frequent. Logging and metrics are crucial "sensing mechanisms" for teams building modern software systems, rather like the radar and video pattern-recognition systems that help autonomous vehicles to travel safely at speed on the highways.
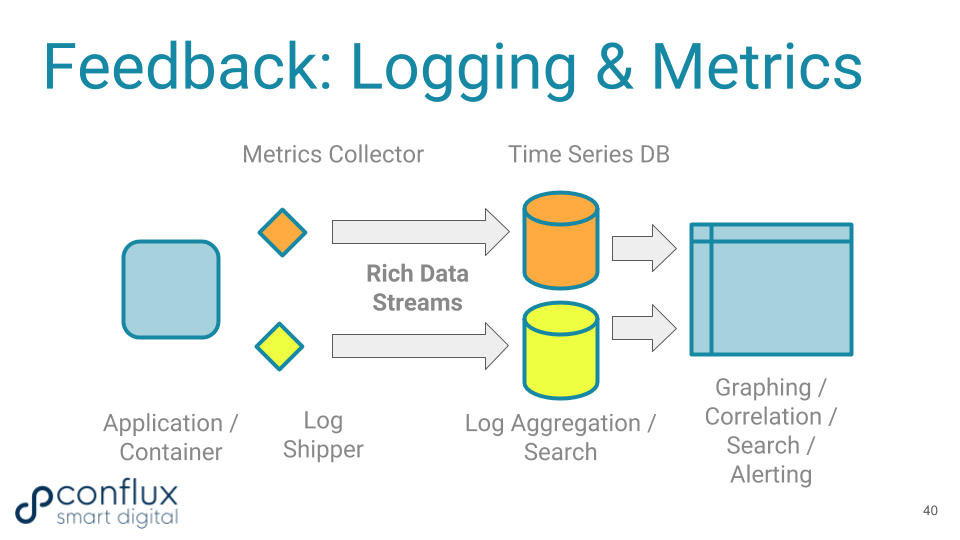
Continuous delivery needs rich telemetry from modern logging and metrics tooling.
Modern software needs good logging. This is a defined set of event types agreed upon between developers and operations people, together with correlation IDs for cross-machine request traceability. Logs are automatically aggregated in a centralized, off-the-shelf logging system that provides access to production log data for developers, testers, and operations people alike through APIs and a browser interface. There is a similar need for aggregated metrics and a shared dashboard and query interface for teams.
5. Underinvestment in build and deployment
Understanding and evolving how we build and deploy our software is absolutely crucial for effective CD. Too many organizations seem to undervalue the importance of focusing on build-and-deployment activities; they prefer instead to add more development teams to focus on "features." These companies don't realize that the cause of delay with feature delivery is often the creaking build-and-deployment systems or the complexity in automated testing.
The organizations that succeed with rapid, reliable software releases invest heavily in build-and-deployment activities. A combination of outsourced (typically SaaS) tooling and a group of experienced build-and-deployment engineers helps to smooth and accelerate the flow of well-tested changes from development to production.
In my experience, a good rule of thumb is to budget for one full-time equivalent person per software development team of seven to nine people. So an organization with eight software development teams should expect to have around eight people dedicated to build and deployment.
Even if all the build-and-deployment tooling is SaaS-hosted, the build-and-deployment people will have a crucial role to play—in considering versioning approaches and interdependencies, evaluating new techniques, splitting and joining components, and ensuring SaaS infrastructure availability. If any tools are run in-house, then the team will need to deal with even more.
6. Not addressing operational aspects well
By adopting CD, organizations are able to respond to business needs more rapidly with an increased pace of delivery. This also means that problems with development practices (such as feature prioritization) are surfaced more rapidly than before. In particular, if operational aspects of the software systems are not addressed every week, features will become ever more difficult to add to the software. This is what I call "feature friction."
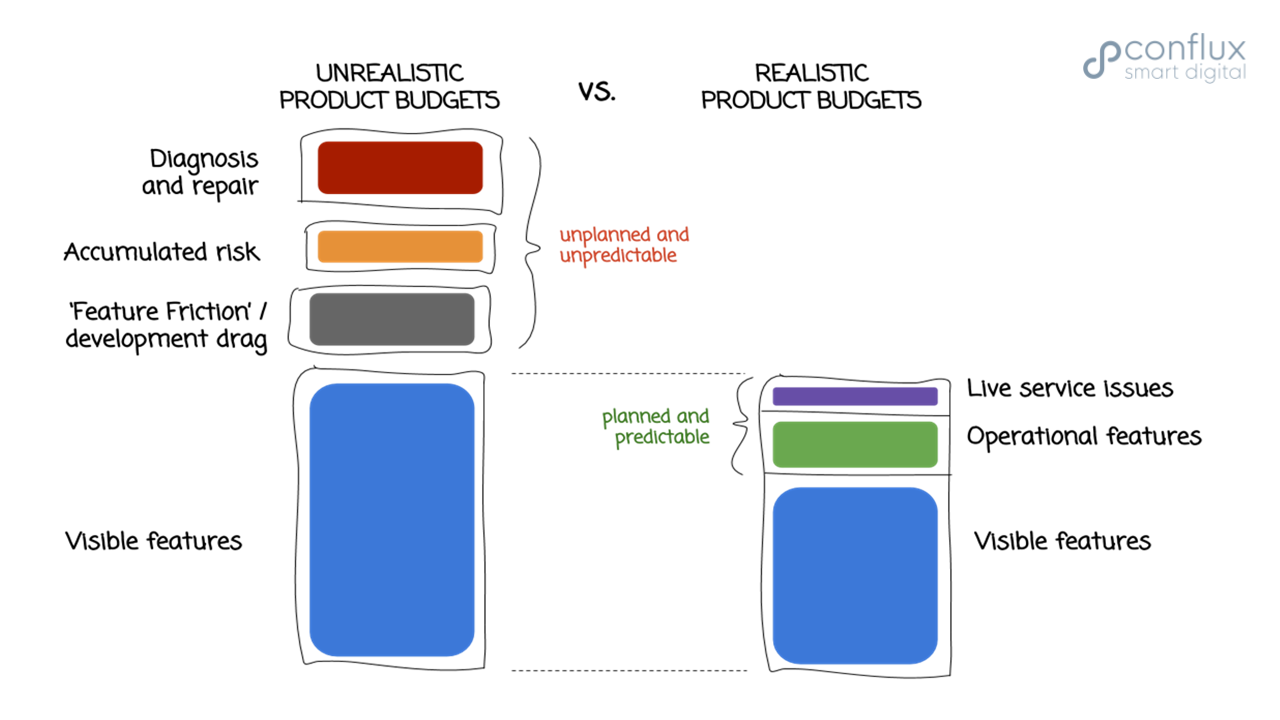
A focus on only visible features leads to increasing feature friction and live service issues.
A good approach is to spend around 30% of product budget each week on operational aspects of the software, such as logging, metrics, ops dashboards, deployment automation, and a planned allocation for dealing with live service incidents. More advanced organizations actually track the amount of time and effort spent on operational aspects and alert if the spend is outside of an accepted range, allowing rapid course correction within a week.
7. Forgetting the database
Let's be honest: CD with data and databases is difficult, although it's easier than it has been in the past. In some organizations, the production databases are "safeguarded" by database administrators (DBAs) and are seen as the definitive version of the database. Usually these production databases have many special tweaks not found elsewhere, such as data manipulation jobs, sharding, or replication settings. These all make it difficult for developers to test database changes in upstream environments, leading to problems in production, which lead to more restrictions on production access, and so on—a vicious circle.
A better approach is to make all database changes flow down from version control in development to production by using one of the many off-the-shelf tools (commercial or free) to evolve the database schema and settings. In this way, only transactional data and new content are created new in production; all other changes are tested before going live, in upstream environments. There are many off-the-shelf tools to choose from, including ApexSQL, ActiveRecord (and similar), DbMaestro, FluentMigrator, Flyway, Liquibase, and a comprehensive suite of tools from Redgate.
8. 'Just plugging in a deployment pipeline'
By its nature, CD emphasizes the importance of build, deployment, and release as key areas of focus for modern software. This means that you may need to refactor or possibly substantially rebuild your software systems to make them more suitable for rapid, reliable releases. Simply putting your existing clunky software into a deployment pipeline and hoping for the best is probably not the ideal approach. Instead, invest in taking the time needed to re-architect your software to make it more suitable for CD.
9. Coveting the 'latest shiny' thing
A perpetual problem in the software industry is the blind pursuit of the next thing—the "latest shiny"—without first addressing core practices and ways of working. At the moment, this is driving a rush toward containers and microservices. But in many cases, the added complexity of these approaches has been ignored. The rapid, reliable software releases we get from CD needs core engineering practices to be in place; otherwise problems occur.
For example, a company in London recently asked me to assess its readiness to move to containers for faster development and deployment. The office was cramped and way too small for the number of people working there, leaving no room for whiteboard discussions, team meetings, etc.
Also, there were no unit tests or integration tests for most of the code, few applications with effective logging or monitoring, and over 200 ETL data processing jobs that existed only in production. To make matters worse, the production database was running on a single server with no high availability or failover. To paraphrase Bridget Kromhout, containers were not going to fix their broken culture.
A checklist to remember
Here are the nine steps to avoid screwing up CD:
- Read the Continuous Delivery book by Humble and Farley.
Use short, wide deployment pipelines that empower decision makers.
Realize that continuous delivery is for you! Think of CD as a set of excellent practices for building working software systems of every kind.
Use good modern logging techniques together with details metrics to drive decision making.
Invest in a ratio of one full-time equivalent for build and deployment activities per nine-person development team.
Spend 30% of product budget on operational aspects every week.
Use an off-the-shelf tool for database changes and drive changes from version control.
Re-architect your software systems to suit CD.
Adopt good software development practices before adding technical complexity.
In the words of Dave Farley, co-author of the Continuous Delivery book, "Continuous delivery is an engineering discipline"; it needs investment to make it work.
Keep learning
Take a deep dive into the state of quality with TechBeacon's Guide. Plus: Download the free World Quality Report 2022-23.
Put performance engineering into practice with these top 10 performance engineering techniques that work.
Find to tools you need with TechBeacon's Buyer's Guide for Selecting Software Test Automation Tools.
Discover best practices for reducing software defects with TechBeacon's Guide.
- Take your testing career to the next level. TechBeacon's Careers Topic Center provides expert advice to prepare you for your next move.
